PyTorch Implementation of Kinect Fusion Algorithm For 3D Reconstruction
Project in brief
Kinect Fusion is a real-time 3D reconstruction algorithm that generates a 3D model of a given scene using a sequence of depth images. There are some standard opensource implementations for the Kinect Fusion algorithm available online. However, most of them are written in C++. This project aims to create a complete python implementation of the Kinect Fusion algorithm and use vectorization with PyTorch to enable GPU acceleration capabilities.

3D Reconstruction results on the livingroom sequence of ICL-NUIM dataset using the implementation code.
Key Steps Of The Kinect Fusion Algorithm
- Capture depth map of the scene.
- Apply bilateral filtering to the depth map.
- Obtain 2.5D representation (vertex map/ pointcloud) by back-projecting depth map to 3D coordinate space.
- Obtain normal vector for each projected point p by computing cross product (p1 - p)x(p2 - p). Where p1 and p2 are the neighboring vertices.
- Store the depth map information by reconstructing the surface using the Truncated Signed Distance Function (TSDF) for MxMxM voxel grid representing a KxKxK cubic meter space. (Store the TSDF values for each voxel in the voxel grid)
- Capture the next depth map and apply steps 2,3 and 4 to it. Let the 2.5D pointcloud obtained be pcl_i and the normal map obtained be nmap_i.
- Using ray casting, obtain global pointcloud pcl_global and global normal map nmap_global.
- Apply (Iterative closest Point) ICP algorithm to find the camera’s pose (rotation and translation) when it captured the depth map in step 5.
- Use the camera pose information obtained in the above step to fuse the TSDF information obtained in step 5 with the global TSDF.
- Repeat step 6 to step 9 until all depth maps are fused.
Vectorized implementation to extract 2.5D ordered pointcloud from an RGB-D Image
In the case of ordered pointcloud, the memory layout of the points is closely related to the spatial layout. This property can be used to speed up the process of calculating normals.
The vectorized implementaiton computes 3D points for each pixel u = (x, y) in the incoming depth map Di(u) parallely. Here K is the 3x3 intrinsic camera matrix. Corresponding 3D points in the camera’s coordinate space are calculated as follows: vi(u) = Di(u) K−1[u, 1]. This results in a single vertex map (2.5 D pointcloud) Vi computed in parallel.
The meshgrid method of PyTorch was used for the GPU accelerated vectorized implementation.
PyTorch Implementation of Iterative Closest Point (ICP) Algorithm
ICP is commonly used for the registration of 3D pointclouds. ICP calculates the rigid transformation that best aligns a source pointcloud to a target pointcloud. In Kinect fusion the source pointcloud is the current 2.5D pointcloud obtained using back-projection, and the target pointcloud is obtained from the reconstructed global 3D model. Hence in this case, the transformation returned by ICP provides the instantaneous global pose of the camera. This is called Frame-to-model tracking.
Kinect Fusion uses Fast ICP which combines projective data-association and point-plane ICP algorithm. The objective function for Fast ICP is as follows:
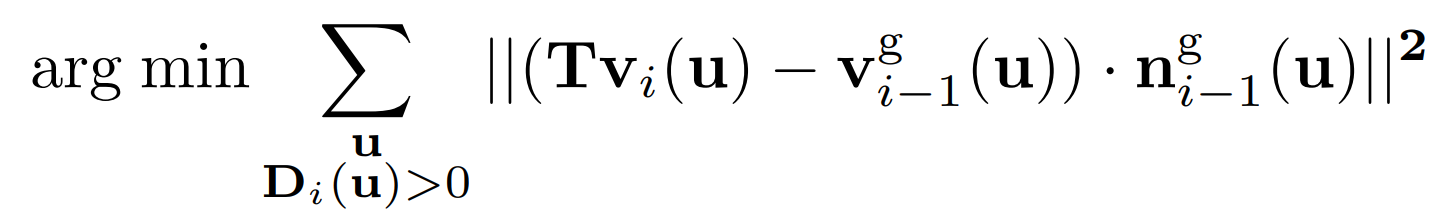
The algorithm for Fast ICP is as follows:

I used PyTorch for vectorized implementation and to enable GPU acceleration capabilities for Fast ICP. The following result illustrates the process of aligning two pointclouds using the vectorized implementation. The pointclouds for the demo were generated using a car model from ShapeNet dataset and the RGB-D images were generated using the renderer provided by PyTorch3D.

RGB and Depth frames of 3D model rendered using PyTorch3D

Iterative alignment of the pointclouds using ICP
PyTorch Implementation of TSDF Fusion Algorithm
Fusing TSDF information is as simple as averaging or weighted sum. It is also easy to optimize. These qualities make TSDF a good choice of representation for the reconstructed 3D model.
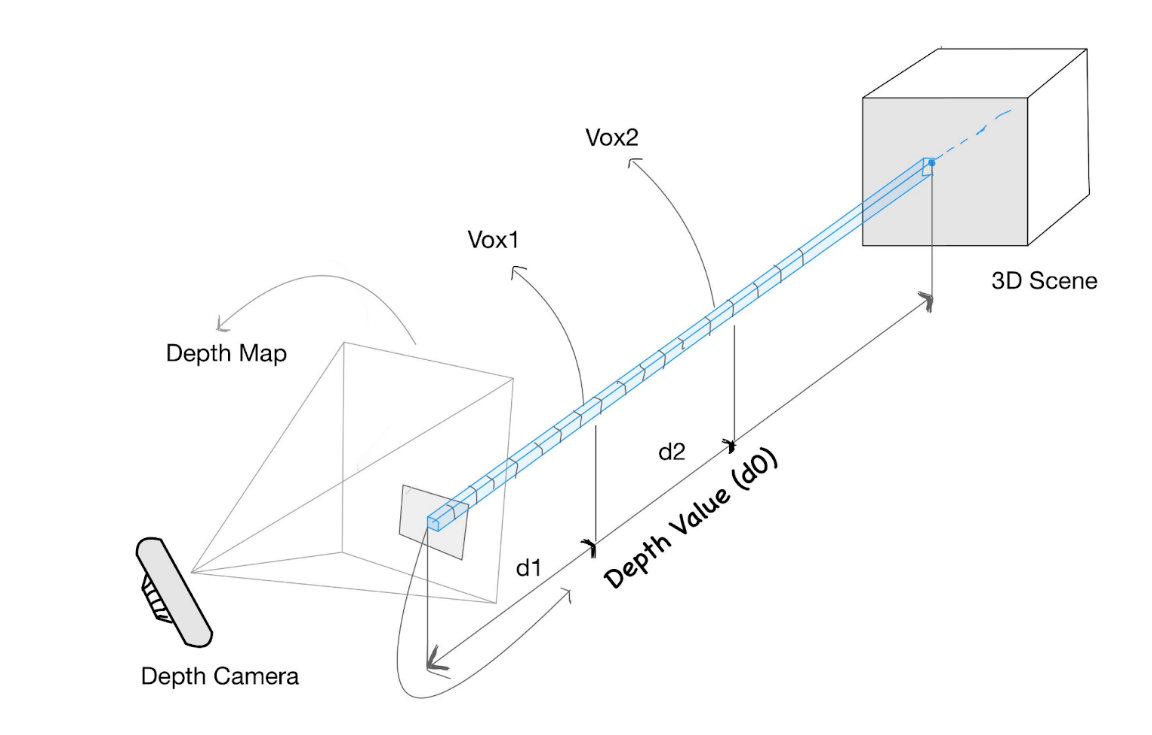
Figure showing how voxels vox1 and vox2 can be projected to the image to obtain corresponding depth values. TSDF(vox1) = d0 - d1 and TSDF(vox2) = d0 - d2.
The TSDF values are updated using weighted averaging only for the voxels that are captured by the camera. A vectorized implementation for this task was written, which provided a mask for all the valid voxels. This, in a way, represents the ray casting step of Kinect fusion. The mask obtained in this stage is used to find the target pointcloud for the fast ICP step.
The PyTorch implementation is inspired by this project, but instead of using marching cubes, I have written a vectorized thresholding based method which further reduces the computation time.
It is important to note that TSDF fusion gives promising results, and most of its components can leverage GPU acceleration capabilities, but at the same time, it is memory expensive. Storing even a 512x512x512 voxel grid representing the 3D volume can require 6GB of GPU RAM. Hence the output depends on the available hardware. Presently I have only implemented TSDF fusion for a fixed size of the voxel grid.
To improve the reconstruction quality, we can divide the entire 3D space into larger sections and represent each section with an NxNxN voxel grid, and only the section visible to the camera can be transferred to GPU. This is similar to voxel hashing. Open3D provides ScalableTSDFVolume class to handle this.
| Voxel Resolution | Memory Required | Avf. Time To Fuse 200 Frames | |
|---|---|---|---|
| (CPU) | (GPU) | ||
| 447 x 398 x 444 | 5.24 GB | 140.81 (s) | 7.32 (s) |
| 224 x 199 x 222 | 2.28 GB | 18.26 (s) | 2.36 (s) |
| 128 x 114 x 127 | 1.5 GB | 6.31 (s) | 0.26 (s) |

GIF showing the global map being reconstructed using the GPU accelerated vectorized implementation of TSDF Fusion using PyTorch. The reconstruction took 10.8 seconds - fusing 1000 RGB-D frames.
Future Work
Currently, the implementation is restricted to a fixed 3D volume. For high-quality, large-scale reconstruction, I am currently using the ScalableTSDFVolume method of Open3D. I plan to add a similar facility to the vectorized implementation.
References
- Izadi, Shahram & Kim, David & Hilliges, Otmar & Molyneaux, David & Newcombe, Richard & Kohli, Pushmeet & Shotton, Jamie & Hodges, Steve & Freeman, Dustin & Davison, Andrew & Fitzgibbon, Andrew. (2011). KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. UIST’11 - Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology.
- Li, Fei & Du, Yunfan & Liu, Rujie. (2016). Truncated Signed Distance Function Volume Integration Based on Voxel-Level Optimization for 3D Reconstruction. Electronic Imaging. 2016. 1-6.
- Original TSDF Fusion library : https://github.com/andyzeng/tsdf-fusion-python.
Project page template inspired from GradSLAM.