LS-HDIB: A Large Scale Handwritten Document Image Binarization Dataset
Kaustubh Sadekar, Ashish Tiwari, Prajwal Singh, Shanmuganathan Raman
Accepted in ICPR 2022.
Abstract
Handwritten document image binarization is challenging due to high variability in the written content and complex background attributes such as page style, paper quality, stains, shadow gradients, and non-uniform illumination. While the traditional thresholding methods do not effectively generalize on such challenging real-world scenarios, deep learning-based methods have performed relatively well when provided with sufficient training data. However, the existing datasets are limited in size and diversity. This work proposes LS-HDIB - a large-scale handwritten document image binarization dataset containing over a million document images that span numerous real-world scenarios. Additionally, we introduce a novel technique that uses a combination of adaptive thresholding and seamless cloning methods to create the dataset with accurate ground truths. Through an extensive quantitative and qualitative evaluation over eight different segmentation models, we demonstrate the enhancement in the performance of the deep networks when trained on the LS-HDIB dataset and tested on unseen images.

A few samples of handwritten document imagesobtained from the proposed LS-HDIB dataset with accurateground truths of the segmented foreground content obtainedusing our dataset generation method
Dataset Details
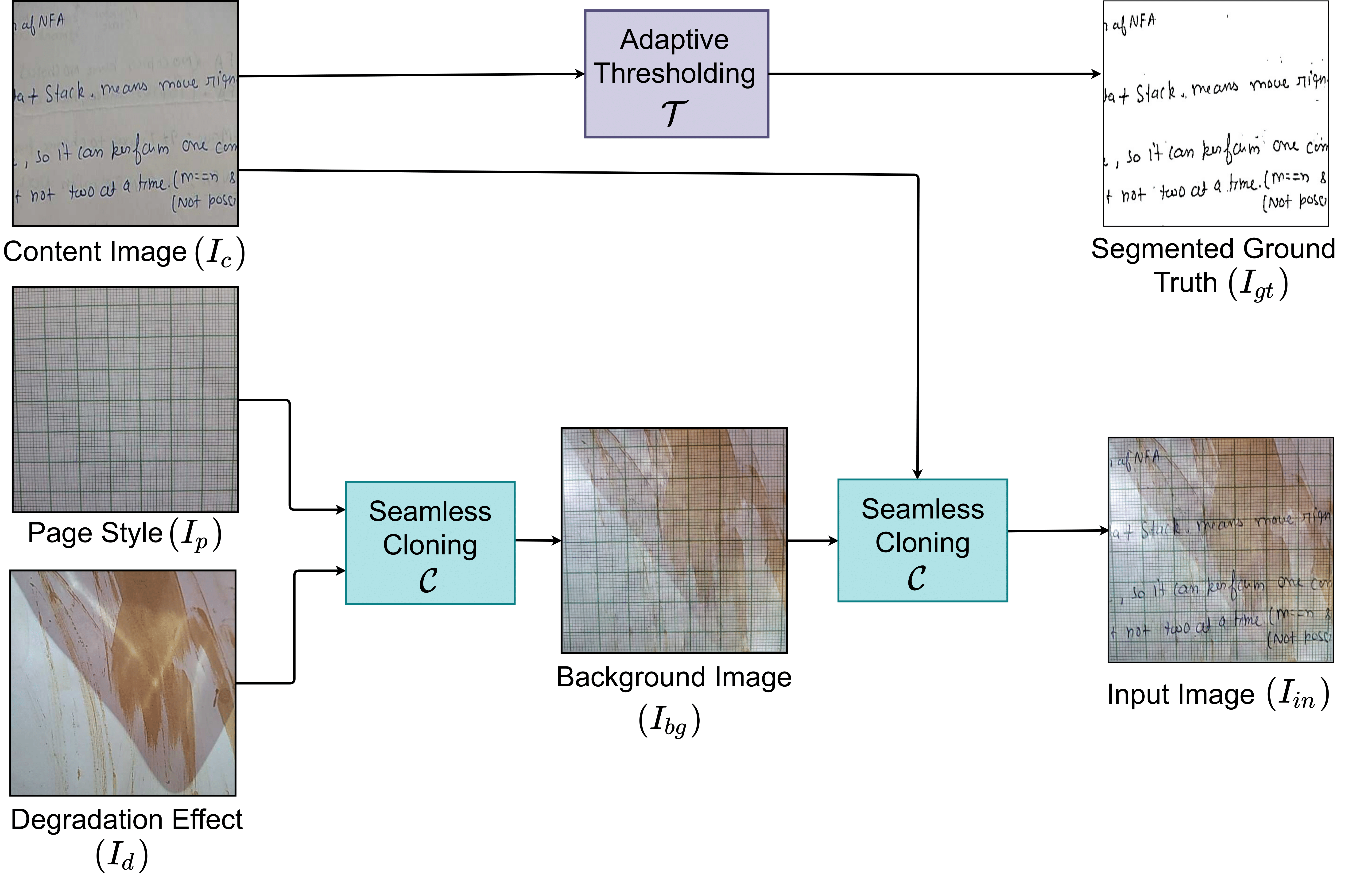
Block schematic of the proposed method for generating LS-HDIB dataset.

A few sample images depicting different page styles available in LS-HDIB dataset.

A few sample images depicting different degradation effects available in LS-HDIB dataset.

A few sample images depicting the variation in the foreground content available in LS-HDIB dataset.
Results
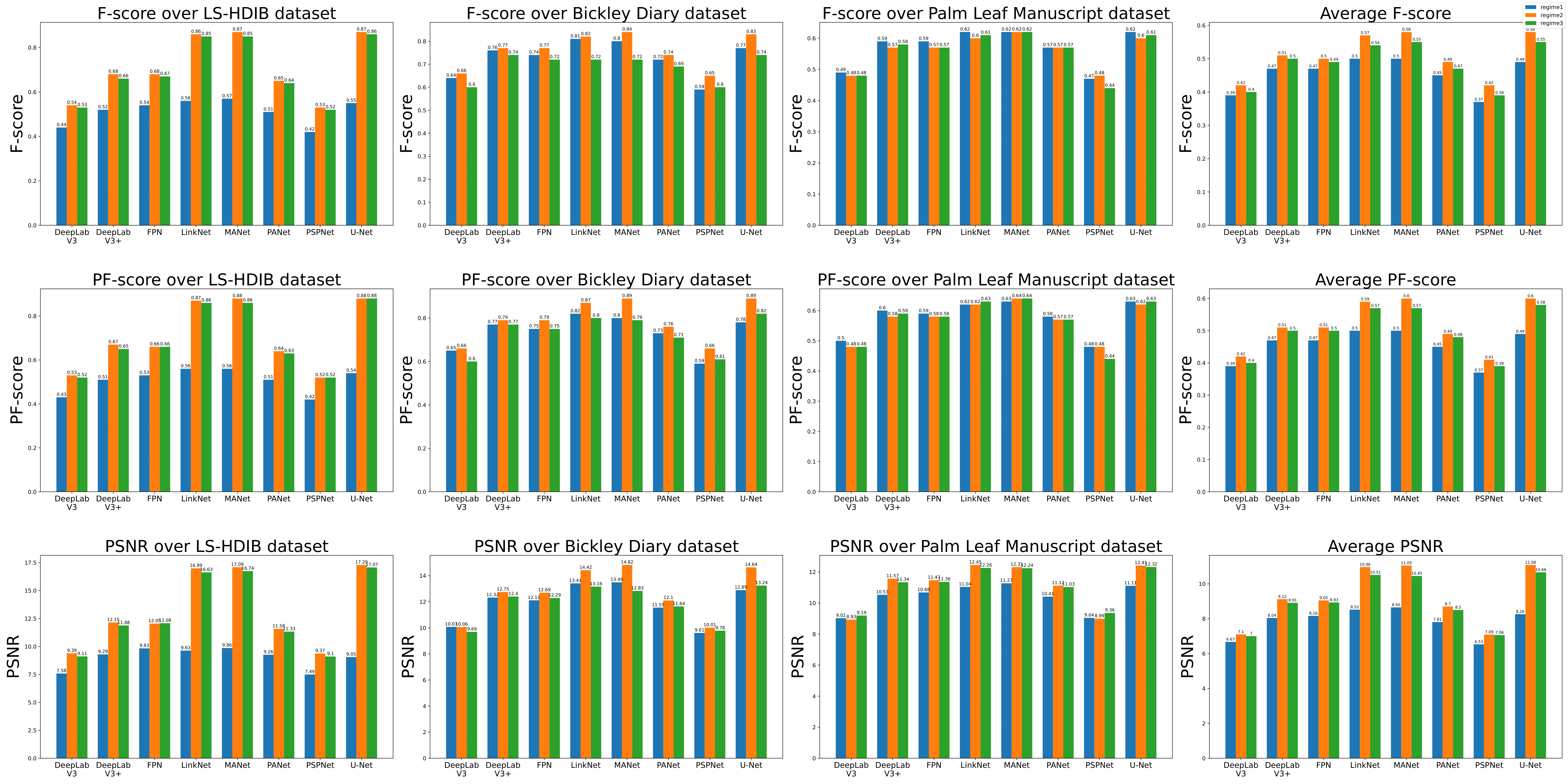
Quantitative comparison of performance of all the eight segmentation models over the three different test datasets when trained under Regime 1 (Blue), Regime 2 (Orange) and Regime 3 (Green).

Qualitative result on the LS-HDIB test dataset.
Qualitative result on the Bickley Diary dataset.
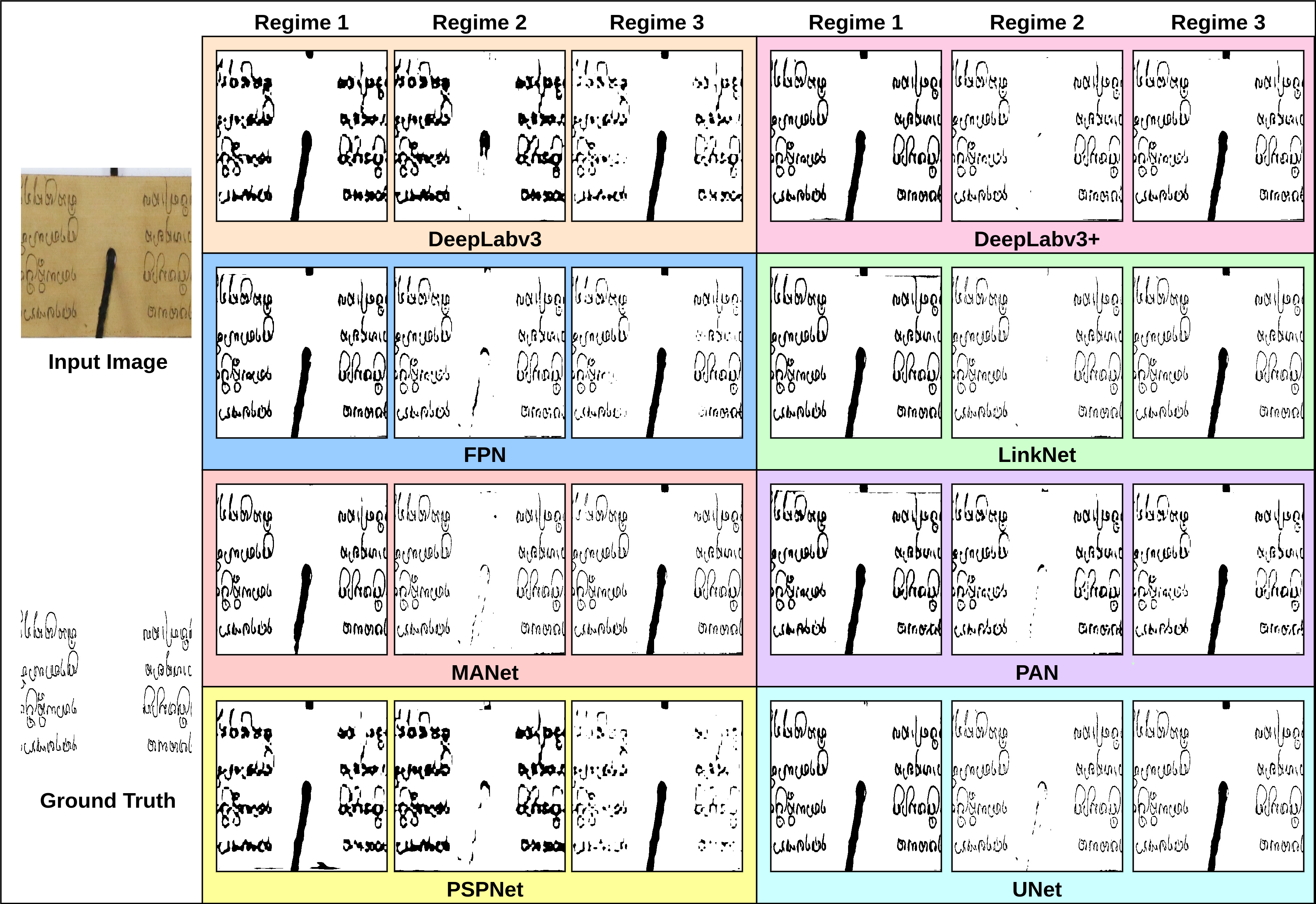
Qualitative result on the Palm Leaf Manuscript dataset.
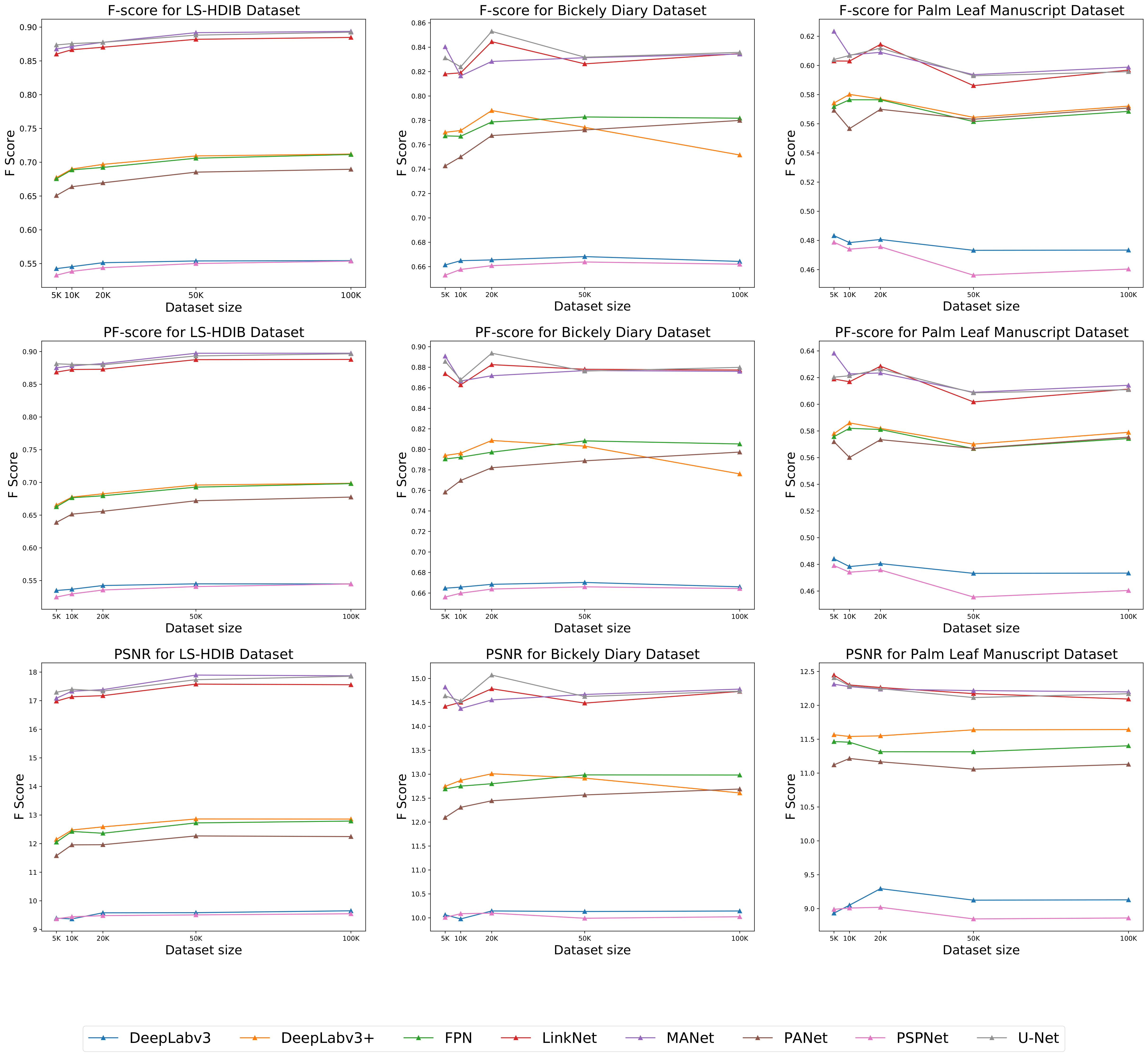
Effect of varying dataset size on the model performance evaluated over the three test datasets.
Citation
If you would like to cite us, kindly use the following BibTeX entry.
@misc{lshdib,
author = {Sadekar, Kaustubh and Tiwari, Ashish and Singh, Prajwal and Raman, Shanmuganathan},
title = {LS-HDIB: A Large Scale Handwritten Document Image Binarization Dataset},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution 4.0 International}
doi = {10.48550/ARXIV.2101.11674},
}
Acknowledgments
This research was supported by Science and Engineering Research Board (SERB) IMPacting Research INnovation and Technology (IMPRINT)-2 grant.
Contact
Feel free to contact Kaustubh Sadekar, Ashish Tiwari or Prajwal Singh for any further discussion about our work.
Project page template inspired from GradSLAM.